

AI小总结(卡哇伊版)
AI正在努力总结中~
前言
P106-100 作为消费级市场性价比极高的算力显卡,搭配飞牛 OS NAS 设备,是个人用户搭建本地私有化大模型服务的最优方案之一。但在实际部署过程中,超 90% 的安装失败、工具拉取异常、容器启动报错,根源都在于软件源配置错误:不兼容 Debian 12 体系的 NVIDIA 旧源、残留的 Ubuntu focal 错误源、失效的 Docker 镜像加速源,会直接导致 NVIDIA 容器工具包安装失败、AI 镜像拉取超时、GPU 资源无法被容器识别。
本教程专为飞牛 OS + P106-100 6GB 显存环境量身打造,严格适配 Debian 12 Bookworm 系统架构,从底层软件源彻底修复、GPU 容器环境配置,到文本推理、图片生成、视频生成三类 AI 服务全流程部署全覆盖,所有操作均经过实测验证,全程可复现,新手也能零踩坑完成落地。
一、前置环境与准备说明
1.1 硬件与软件基础要求
| 项目 | 最低要求 | 推荐配置 |
|---|---|---|
| 核心硬件 | P106-100 6GB 显存显卡、飞牛 OS 设备 | P106-100 显卡、x86 架构飞牛 OS 设备、16GB 以上内存、SSD 固态硬盘(AI 数据目录挂载) |
| 系统环境 | 飞牛 OS 正式版、Docker 服务已预装 | 飞牛 OS 最新稳定版、Docker 服务已启用并开机自启 |
| 操作权限 | SSH 远程连接权限、sudo 管理员权限 | 完整 SSH 管理员权限、系统防火墙已放行对应端口 |
1.2 核心踩坑点前置说明
飞牛 OS 基于 Debian 12 Bookworm 开发,错误使用 Ubuntu 20.04(focal)系列源、残留 NVIDIA 旧配置、Docker 加速源失效,是部署失败的三大核心元凶。本教程将优先完成底层环境的彻底清理与修复,再进行 AI 服务部署,从根源规避 90% 以上的报错问题。
二、第一步:彻底清理错误源与旧配置,根治依赖冲突
在添加新的软件源前,必须彻底清理系统内残留的错误源、旧配置与失效密钥,避免新旧配置冲突导致 apt 更新报错、依赖安装失败。
SSH 连接飞牛 OS 设备,依次执行以下命令:
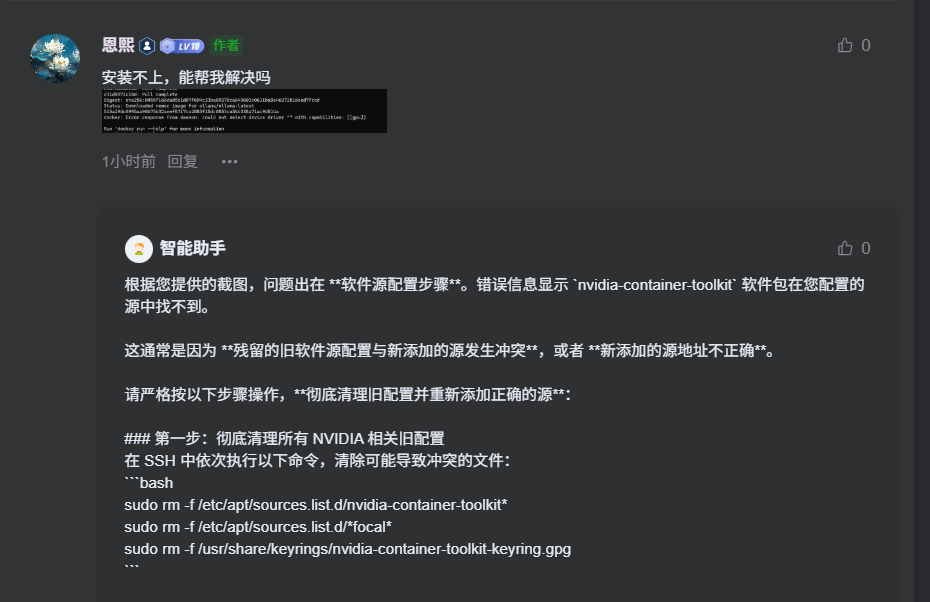
# 1. 删除所有NVIDIA相关旧源文件,避免版本冲突
sudo rm -f /etc/apt/sources.list.d/nvidia-container-toolkit*# 2. 删除错误的focal系列源(Ubuntu 20.04源与Debian 12不兼容)
sudo rm -f /etc/apt/sources.list.d/*focal*# 3. 清理失效的NVIDIA旧密钥文件,解决签名校验失败问题
sudo rm -f /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg三、第二步:适配 Debian 12 的 NVIDIA 官方源配置与环境安装
这一步是核心,只有正确配置 NVIDIA 容器工具包源并完成安装,Docker 容器才能正常调用 P106-100 显卡的 GPU 算力,否则会出现 “容器内无法识别 GPU” 的核心报错。
3.1 安装前置依赖工具
先安装密钥导入、源配置所需的基础工具,避免后续命令执行失败:
sudo apt update && sudo apt install -y --no-install-recommends curl gnupg2 ca-certificates3.2 导入 NVIDIA 官方 GPG 密钥
通过官方地址导入合法 GPG 密钥,解决软件包签名校验失败问题,官方密钥内容可参考 NVIDIA 开源仓库:
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg如果上面步骤没问题就不用管这个,如果无法安装,就按这个操作,国内网络访问官方地址超时,可替换为中科大镜像源地址:
curl -fsSL https://mirrors.ustc.edu.cn/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg3.3 添加适配 Debian 12 的 NVIDIA 官方软件源
飞牛 OS 基于 Debian 12,NVIDIA 已采用统一 deb 包适配所有 Debian 系发行版,无需寻找专属 Bookworm 源,直接使用兼容 ubuntu22.04 的官方稳定源即可:
# 添加官方稳定源,并自动绑定已导入的密钥文件
curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list# 【可选】开启实验性源,解决部分特殊依赖缺失问题
sudo sed -i -e '/experimental/ s/^#//g' /etc/apt/sources.list.d/nvidia-container-toolkit.list如果上面步骤没问题,就不用管,如果无法安装,就按照这个操作,国内网络优化方案,替换为中科大镜像源:
curl -s -L https://mirrors.ustc.edu.cn/libnvidia-container/stable/deb/nvidia-container-toolkit.list | sed 's#deb https://nvidia.github.io#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://mirrors.ustc.edu.cn#g' | sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list3.4 安装 NVIDIA 容器工具包并完成配置
1.更新软件源缓存,验证源配置是否生效:
sudo apt update2.安装 NVIDIA 容器工具包核心组件:
sudo apt install -y nvidia-container-toolkit3.配置 Docker 的 NVIDIA 运行时,让 Docker 支持 GPU 资源调用:
sudo nvidia-ctk runtime configure --runtime=docker4.重启 Docker 服务,让所有配置生效:
sudo systemctl daemon-reload
sudo systemctl restart docker3.5 GPU 环境有效性终极验证
执行以下命令,若终端正常输出 P106-100 显卡的 CUDA 信息、显存状态,即说明底层环境配置完成,可正常进行后续 AI 服务部署:
docker run --rm --gpus all nvidia/cuda:11.8-base nvidia-smi四、第三步:Docker 镜像源全量修复,解决镜像拉取失败问题
完成 GPU 环境配置后,需修复 Docker 镜像源。经实测,传统的中科大、网易、轩辕镜像部分地址已出现
invalid link、网页解析失败、分页请求超出范围等异常,需替换为 2026 年最新可用的国内加速源,根治镜像拉取超时、失败问题。4.1 先排查 Docker 当前源状态
执行以下命令,查看 Docker 当前加载的镜像源配置,确认是否存在失效地址:
docker info | grep "Registry Mirrors"4.2 写入标准可用的 Docker 加速配置
通过以下命令强制覆盖daemon.json配置文件,彻底解决 JSON 格式错误、源失效问题,配置中已筛选 2026 年国内稳定可用的镜像源:
cat > /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": [
"https://docker.m.daocloud.io",
"https://docker.1ms.run",
"https://docker.nju.edu.cn",
"https://mirrors.tuna.tsinghua.edu.cn/docker"
],
"insecure-registries": [],
"debug": false,
"experimental": false
}
EOF4.3 重载配置并验证 Docker 服务状态
# 重载系统服务配置
sudo systemctl daemon-reload# 重启Docker服务
sudo systemctl restart docker# 验证Docker服务运行状态,需显示active (running)无报错
sudo systemctl status docker4.4 飞牛 OS 可视化界面补充配置
为确保界面操作与命令行配置一致,完成以上操作后,需在飞牛 OS 界面同步配置:
- 打开飞牛 OS 桌面,进入 Docker 应用
- 找到「镜像仓库」模块,点击右上角「设置」
- 进入「加速源设置」,添加上述可用的加速源地址
- 保存配置后,重启 Docker 应用生效
五、文本大模型服务部署:Ollama + Open WebUI 全流程
完成底层环境修复后,优先部署文本大模型服务,这是 P106-100 6GB 显存最适配的场景,可实现本地私有化 ChatGPT 式对话体验,全程不消耗外网带宽,数据完全本地化。
5.1 Ollama 推理后端 Docker 一键部署
Ollama 是目前最轻量化、兼容性最强的大模型推理框架,支持一键部署、模型快速拉取,适配 P106-100 显卡。以下命令已做好资源硬限制,避免 AI 服务占用过多资源影响 NAS 正常运行:
docker run -d --gpus all \
--name ollama \
--restart always \
--cpus 3 \
--memory 10g \
--memory-swap 10g \
-v /volume1/AI/ollama:/root/.ollama \
-p 11434:11434 \
ollama/ollama参数说明:
--gpus all:给容器分配所有 GPU 资源,实现硬件加速--cpus 3/--memory 10g:限制 CPU 核心数和内存占用,避免 NAS 卡死-v:挂载 NAS 本地目录,模型文件持久化存储,重启容器不丢失-p 11434:11434:端口映射,后续 WebUI 通过该端口对接推理后端
5.2 适配 P106-100 6GB 显存的模型推荐与拉取
以下模型均经过实测,可在 6GB 显存下稳定运行,无爆显存风险,按需拉取即可:
| 模型类型 | 推荐模型 | 资源占用 | 适用场景 | 运行模式 |
|---|---|---|---|---|
| 日常常驻轻量模型 | qwen2:1.5b-instruct-q4_0 | 显存 < 1GB,内存 < 1GB | 日常闲聊、简单问答、轻量文本处理 | 7×24 小时常驻,完全不影响 NAS 运行 |
| 全能重载模型 | qwen2:7b-instruct-q4_0 | 显存 4-5GB,内存 6-8GB | 深度逻辑推理、长文本处理、多轮对话 | 按需启用,用完切回轻量模型 |
| 代码专项模型 | deepseek-coder:6.7b-instruct-q4_0 | 显存 4-5GB,内存 6-8GB | 代码编写、调试、注释、逻辑解读 | 按需启用,用完关闭 |
模型拉取命令(SSH 中执行即可):
# 拉取日常常驻轻量模型(必选,新手优先)
docker -it ollama ollama pull qwen2:1.5b-instruct-q4_0# 拉取全能7B模型(可选,深度场景使用)
docker -it ollama ollama pull qwen2:7b-instruct-q4_0# 拉取代码专项模型(可选,代码场景使用)
docker -it ollama ollama pull deepseek-coder:6.7b-instruct-q4_05.3 Open WebUI 可视化界面 Docker 部署
Open WebUI 是类 ChatGPT 的开源可视化操作界面,完美适配 Ollama 后端,支持手机 / 电脑内网访问、多模型切换、对话管理、代码高亮、文件解析等功能,一键部署即可使用:
docker run -d \
--name open-webui \
--restart always \
--cpus 1 \
--memory 2g \
-v /volume1/AI/open-webui:/app/backend/data \
-p 3000:8080 \
--add-host=host.docker.internal:host-gateway \
ghcr.io/open-webui/open-webui:main部署完成后,浏览器访问
飞牛OS内网IP:3000,即可打开可视化界面,首次访问注册管理员账号,即可选择已拉取的模型开始对话。六、图片生成服务部署:Stable Diffusion WebUI 6GB 显存极致优化
基于 Stable Diffusion WebUI 搭建本地 AI 绘画服务,针对 P106-100 6GB 显存做了极致优化,可将显存占用压缩至 4GB 以内,彻底解决爆显存、闪退问题,实现本地私有化图片生成。
6.1 SD WebUI Docker 一键部署
docker run -d \
--name sd-webui \
--gpus all \
--restart unless-stopped \
--cpus 2 \
--memory 8g \
-p 7860:7860 \
-v /volume1/AI/sd-webui/models:/app/models \
-v /volume1/AI/sd-webui/outputs:/app/outputs \
--ipc=host \
abdbarho/stable-diffusion-webui-docker:latest关键说明:
- 挂载
models目录,可直接将下载的 SD 模型文件放入 NAS 对应文件夹,无需进入容器操作- 挂载
outputs目录,生成的图片直接保存到 NAS 本地,方便查看和管理- 部署完成后,浏览器访问
飞牛OS内网IP:7860即可打开 WebUI 界面
6.2 6GB 显存必做的启动参数优化
这一步是 P106-100 稳定运行的核心,不添加优化参数必出现爆显存、半精度运算报错、生成速度极慢等问题。
在 SD WebUI 启动参数中添加以下配置,即可适配 6GB 显存:
--xformers --medvram --opt-sdp-attention --no-half-vae --disable-nan-check核心优化参数说明:
--medvram:开启中显存模式,专为 6GB 显存硬件优化,平衡显存占用与生成速度--xformers:开启注意力机制优化,大幅降低显存占用,提升图片生成速度--no-half-vae:关闭半精度运算,彻底解决 P106-100 显卡半精度运算报错、黑图问题--opt-sdp-attention:进一步优化显存占用,兼容 P106 显卡的算力架构
6.3 适配硬件的模型推荐
- 首选:SD1.5 系列模型(如 ChilloutMix、Deliberate、MeinaMix):模型大小 2-4GB,6GB 显存无压力运行,512×768 分辨率单图生成仅需 8-15 秒,新手首选。
- 进阶可选:SDXL-Turbo 轻量化量化模型:768×768 分辨率 4 步采样即可出图,单图生成仅需 10-20 秒,使用时需关闭其他所有 AI 服务,独占显存资源。
七、轻量化视频生成服务部署:SVD WebUI 低显存专属方案
P106-100 6GB 显存是视频生成的核心瓶颈,仅能运行短时长、低分辨率的轻量化视频生成模型,本方案采用 Stable Video Diffusion(SVD)轻量化 WebUI,是目前 6GB 显存能稳定运行的最优方案,支持图片生成视频、文生视频。
重要使用须知:视频生成服务必须关闭其他所有 AI 容器,独占 GPU 和内存资源,生成完成后立刻关闭容器,完全释放资源,避免影响 NAS 运行和其他服务。
7.1 SVD WebUI Docker 一键部署
docker run -d \
--name video-webui \
--gpus all \
--restart unless-stopped \
--cpus 3 \
--memory 10g \
-p 7861:7860 \
-v /volume1/AI/video-webui/models:/app/models \
-v /volume1/AI/video-webui/outputs:/app/outputs \
--ipc=host \
ysdnchina/svd-webui:latest部署完成后,浏览器访问
飞牛OS内网IP:7861即可打开视频生成 WebUI 界面。7.2 6GB 显存稳定运行的启动优化参数
在启动参数中添加以下配置,确保 6GB 显存下稳定运行,无闪退、爆显存问题:
--xformers --medvram --opt-sdp-attention --no-half --load-in-4bit核心优化说明:
--load-in-4bit开启 4bit 量化加载,大幅降低模型显存占用,是 6GB 显存能运行视频生成模型的核心配置;--no-half关闭半精度运算,适配 P106-100 显卡架构,避免运算报错。八、常见问题排查与运维指南
8.1 apt update 报错相关
- 签名校验失败:返回第一步检查旧密钥是否清理干净,重新执行官方 GPG 密钥导入命令
- 源地址 404 / 找不到:检查是否残留 focal 旧源,Debian 12 不可使用 Ubuntu 20.04 系列源,重新执行源清理步骤
- 依赖冲突 / 无法安装:开启实验性源,执行
sudo apt update && sudo apt upgrade -y更新系统依赖后重试
8.2 容器内无法识别 GPU 相关
- nvidia-smi 命令报错:检查 nvidia-container-toolkit 是否安装成功,重新执行安装命令并重启 Docker
- –gpus all 参数无效:执行
sudo nvidia-ctk runtime configure --runtime=docker重新配置 NVIDIA 运行时,重启 Docker 服务 - 显卡驱动版本不兼容:飞牛 OS 更新显卡驱动至最新稳定版,重新执行环境验证命令
8.3 Docker 镜像拉取失败相关
- 超时 /invalid link:替换 daemon.json 中的镜像源为最新可用地址,优先使用 DaoCloud、毫秒镜像
- 镜像拉取权限报错:检查 daemon.json 的 JSON 格式是否正确,重启 Docker 服务后重试
- 飞牛 OS 界面拉取失败:确保界面加速源配置与命令行配置一致,重启 Docker 应用生效
8.4 AI 服务爆显存 / 闪退相关
- SD WebUI 生成图片闪退:检查是否添加了
--medvram --no-half-vae优化参数,关闭其他 AI 容器释放显存 - Ollama 模型加载失败:优先使用 q4_0 量化版本模型,降低内存和显存占用,检查内存限制是否合理
- 视频生成服务崩溃:必须关闭所有其他 AI 容器,独占 GPU 资源,降低生成视频的分辨率和时长
结尾
本教程完整覆盖了飞牛 OS + P106-100 环境下,从底层软件源修复、GPU 容器环境配置,到文本推理、图片生成、视频生成三类 AI 服务的全流程部署。所有操作均针对 6GB 显存硬件做了极致优化,同时兼顾了 NAS 系统的稳定性,新手用户可按照教程步骤逐行执行,零踩坑完成本地私有化大模型服务的搭建。
建议新手用户优先完成文本大模型的部署与测试,熟悉操作后,再逐步尝试图片生成、视频生成等进阶场景,充分发挥 P106-100 显卡的闲置算力价值。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END



- 最新
- 最热
只看作者